S3=>이미지 업로드용 이건 확실히 알겠다,하지만 여러 서비스가 있는데 왜 S3를 쓰는지가 궁금했다.
AWS S3?
Simple Storage Service(S3)는 인터넷용 스토리지 서비스이다.
이 서비스는 개발자가 더 쉽게 웹 규모 컴퓨팅 작업을 수행할 수 있도록 설계되었다
특징
높은 내구성(유실 가능성이 희박)과 높은 가용성,저렴한 가격으로 제공
> 내부적으로 복제되어 데이터가 손상되더라도 복구가능 - 내구성
> SSL을 통한 데이터 전송,업로드 후 자동 암호화 지원 & IAM을 사용해 객체 권한을 관리하고 데이터에 대한
액세스를 제어하는 버킷 정책을 구성할 수 있음-보안
> S3에 파일 업로드되었을 때 다른 서비스에 알림(Trigger)를 보내 동작하게 가능
용도
1. 컨텐츠를 저장하고 배포할 때 사용
예시) 웹사이트를 만들 때 사용자들이 파일을 전송하면 그 파일을 S3에 저장하고 S3에서 다운받아 다른 사용자에게 제공
2. 빅 데이터 분석 📚
S3 객체 스토리지
S3의 가장 큰 특징인 높은 내구성과 가용성을 제공하도록 설계함
일반 객체스토리지는 기본적으로 내부 복제를 하는데 하나의 단위 객체가 업로드되면 자동으로 내부의 여러 위치에 복제본을 생성한다. 이와 똑같은 구조로 S3 객체스토리지 또한 동일 Region내에 여러 AZ에 걸쳐 복제본을 생성한다.
아래 일반 객체 스토리지의 예시를 보자.

장점
☛ 내부적으로 복제가 수행되면 어느 한 객체에 손상이 발생하더라도 손상되지 않은 복제본이 있기 때문에 내구성 상승
예시) 어느 하나 객체 손상 확률 10%, 원본을 포함해 총 3개의 복제본이 생성되었다면 모든 객체가 손상될 확률은 10% * 10% * 10% = 0.001%가 된다)
☛ 복제본도 원본과 동일하게 실제 다운로드 요청에 응답하는데 사용되기 때문에 가용성 또한 상승
단점
☛ 내부 복제에 일정한 시간이 소요되기 때문에 내부 복제가 모두 완료(Fully Propagated)되기 이전에는 각기 다른 객체의 위치에서 응답하므로 사용자별로 일관되지 않은 응답이 발생할 수 있다.
예시)
1. Create(새로 쓰기)할 경우 일부 요청에 객체 목록이 표시되지 않음
2. Overwrite(덮어 쓰기)할 경우 일부 요청에 이전 버전의 객체를 응답함
3. Delete(삭제)할 경우 일부 요청에 삭제되기 전의 객체가 표시되거나 응답함
물론 이러한 현상은 일시적인 것이며, 일정 시간(수초 이내)이 지난 후에는 내부 복제가 모두 완료되어 모든 사용자에게 일관된 응답을 제공한다.
이를 Eventual Consistency(최종 일관성)을 제공한다라고 말하며, 이는 객체스토리지 특성이자 S3의 특성이다.
객체 스토리지 및 S3가 공통적으로 갖고있는 특성
- 객체 생성(Create) 및 삭제(Delete)만 지원한다. 수정(Update)은 지원하지 않는다. 덮어쓰기도 가능하지만 이는 내부적으로 수정 처리하는 것이 아니라 동일한 경로에 재생성하는 방식이다.
- 객체 데이타와 관련된 각종 부가정보(날짜, 사용자정보 등)는 객체 데이터 외부에 별도로 저장하여 관리한다. 이러한 부가정보를 Metadata라고 부르며 "Key-Value"형태로 항목을 자유롭게 추가하여 관리할 수 있다.
- 각 객체의 주소값은 글로벌하게 고유해야 한다. 사용자가 인터넷을 통해 단위 객체에 접근하기 때문이다. S3의 경우 Key: [버킷명+Key값+버전ID]로 각 객체를 구분한다.
- HTTP(S) 프로토콜을 사용하여 업로드/ 다운로드를 수행할 수 있다
S3 버킷(Bucket)과 객체(Object)
S3에는 버킷과 객체로 불리는 단위가 있다.
객체는 파일 및 파일정보로 구성된 저장 단위이고
버킷은 다수의 객체를 통합하여 저장/ 관리/ 제어하는 일종의 바구니(Container)라고 생각하면 된다.
버킷 생성
버킷의 이름과 버킷이 위치할 Region을 선택한다.
→ (버킷의 이름은 전 셰계적으로 고유(Unique)해야 한다.)
버킷명은 이후 인터넷을 통해 객체를 호출할 때 주소값의 가장 앞에 위치하며, 버킷명이 고유하므로 버킷명을 포함한 객체 주소도 글로벌하게 고유한 주소값을 갖는다.
S3 접근제어
S3는 두가지 범주의 작업(Operation)이 있다.
- Bucket Operation : 버킷 생성, 버킷 삭제, 버킷 속성변경 등 버킷 단위의 작업
- Object Operation : 객체 생성, 객체 삭제, 객체 다운로드 등 객체 단위의 작업
이러한 두 가지 범주의 작업을 제어하는 권한 계층에는 다음의 세 가지가 있다.
☛ Bucket ACL과 Object ACL은 XML로 설정한다. Bucket ACL은 버킷 단위 작업의 권한을 Object ACL은 객체 단위 작업의 권한을 제어한다. 하지만 이 둘은 예전의 제어 방식이며, 여러 제약사항으로 사용을 권장하지 않는다. 그냥 있다고만 인식하고 있으면 된다.
☛ Bucket Policy는 JSON형식으로 접근권한을 정의한다. 버킷 단위 작업과 객체 단위 작업을 모두 정의할 수 있으며, 정의하는 권한범위 또한 제한이 없다. 따라서 S3와 관련된 접근정책은 거의 Buckey Policy를 사용하는 것이 좋다
+ 버킷 및 객체 권한은 서로 독립적이다. 객체는 해당 버킷으로부터 권한을 상속하지 않는다.
* 예를 들어, 버킷을 만들고 사용자에게 쓰기 액세스 권한을 부여하는 경우 사용자로부터 명시적으로 권한을 부여 받지 않는 한 해당 사용자의 객체에 액세스할 수 없다.
S3 Storage Class
S3는 여러 가지 종류의 Storage Class를 제공한다.
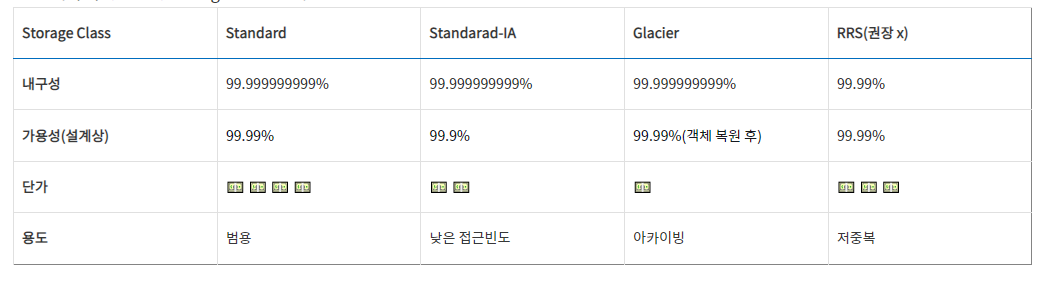
자신이 S3에 쓰는 용도에 따라 Storage Class를 잘 골라야한다.
Class별로 과금요소가 다르기 때문에 단순히 어느 것이 가장 비싸고 싸다고 정의할 수는 없다. (참고)
Standard-IA의 경우 객체별로 과금되는 최소 용량 단위(128KB)가 있고 데이터 복구시 추가 요금이 발생한다.
Glacier 또한 백업 용도의 Storage Class로 실제 데이터를 불러오는데 추가 시간과 비용이 발생한다.
보통 장기적으로 데이터 보관을 위한 용도면 Glacier가 적합하고, 장기 스토리지나 백업 및 복구 파일용 데이터 저장소로는 Standard-IA가 적합하다.
참고:
https://loosie.tistory.com/206
https://aws.amazon.com/ko/s3/storage-classes/
https://docs.aws.amazon.com/ko_kr/AmazonS3/latest/userguide/storage-class-intro.html
https://docs.aws.amazon.com/ko_kr/AmazonS3/latest/userguide/managing-acls.html
'책벌레와 벌레 그 사이 어딘가 > 개념쌓기' 카테고리의 다른 글
| [개념쌓기]ElasticSearch ,데이터 사이언스 (0) | 2022.09.21 |
|---|---|
| [개념쌓기]ElasticSearch ,검색 엔진 ? 검색시스템? (0) | 2022.09.13 |
| [개념쌓기]타임리프/API/SDK/JDK (0) | 2022.08.30 |
| [개념쌓기] Docker (0) | 2022.08.26 |
| [개념쌓기] 로드밸런싱? (0) | 2022.08.25 |




댓글